# basics
import numpy as np
# machine learning
from sklearn.datasets import make_blobs
from sklearn.tree import DecisionTreeClassifier, plot_tree, export_text
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScalerDecision Trees for Classification
Splitting with Gini and Entropy
Notebook
The following Jupyter notebook contains some starter code that may be useful for following along with this note.
Notes from Lecture
TODO
Classification
{'ccp_alpha': 0.0,
'class_weight': None,
'criterion': 'gini',
'max_depth': None,
'max_features': None,
'max_leaf_nodes': None,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'monotonic_cst': None,
'random_state': None,
'splitter': 'best'}array([[0. , 0. , 1. ],
[0.8030303 , 0.04545455, 0.15151515],
[0.18421053, 0.81578947, 0. ],
[0.18421053, 0.81578947, 0. ],
[0.18421053, 0.81578947, 0. ],
[0.18421053, 0.81578947, 0. ],
[0.18421053, 0.81578947, 0. ],
[0. , 0. , 1. ],
[0. , 0. , 1. ],
[0.18421053, 0.81578947, 0. ]])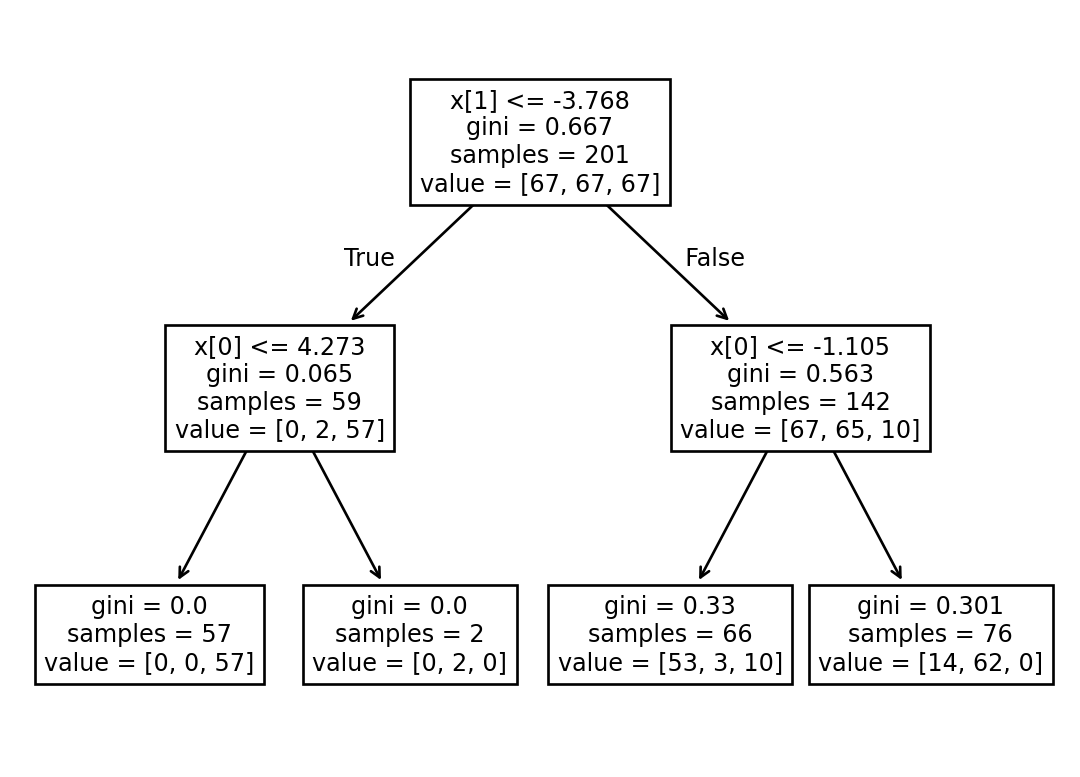
|--- feature_1 <= -3.77
| |--- feature_0 <= 4.27
| | |--- weights: [0.00, 0.00, 57.00] class: 2
| |--- feature_0 > 4.27
| | |--- weights: [0.00, 2.00, 0.00] class: 1
|--- feature_1 > -3.77
| |--- feature_0 <= -1.11
| | |--- weights: [53.00, 3.00, 10.00] class: 0
| |--- feature_0 > -1.11
| | |--- weights: [14.00, 62.00, 0.00] class: 1
Effects of Scaling
array([[-5.96100255e+00, -1.75622930e+02],
[-2.13550500e+00, 1.42525049e+02],
[ 1.72490722e-01, 8.87049143e+01],
[ 1.31367044e-03, -5.95708523e+01],
[ 6.24031968e-01, 7.56488248e+01],
[ 1.07614212e+01, -6.77972097e+01],
[ 4.81077324e+00, -9.40663239e+00],
[-9.32064131e-01, -2.30438354e+02],
[-3.83139425e+00, -9.03800287e+01],
[ 1.16388957e+00, 3.49989920e+01]])[2 0 0 1 0 1 1 2 2 0 1 0 0 1 2 0 2 2 2 2 1 1 1 1 0]
[2 0 1 1 1 1 1 2 2 1 2 0 2 1 2 0 2 2 2 2 1 1 0 1 0]